(int)(Math.random() * (65535 + 1)) returns a random number __________.A. between 1 and 65536B. between 1 and 65535C. between 0 and 65535D. between 0 and 65536
Answers
The expression `(int)(Math.random() * (65535 + 1))` returns a random number between 0 and 65535.
How the random function works?The minimum value of the random is zero, Then between 1 - 65536 is no considered because the sum of one does not affect the higher range and minimum range can not be 1.
So, Correct answer is between 0 and 65535.
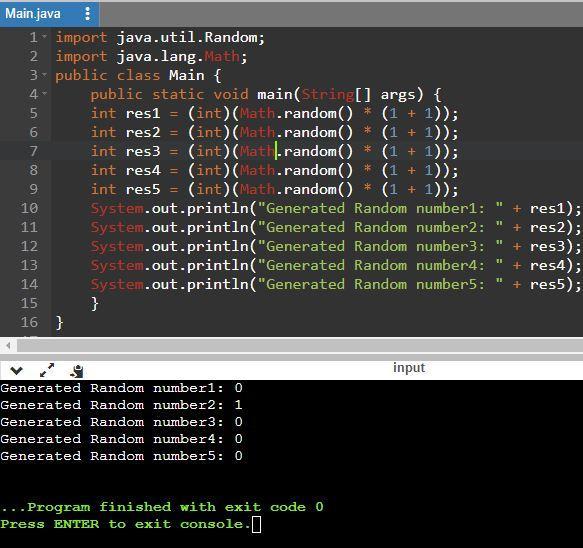
In the following Java code you can see that although the upper bound is 1+1, the range of the random function is 0-1.
Java code:import java.util.Random;
import java.lang.Math;
public class Main {
public static void main(String[] args) {
int res1 = (int)(Math.random() * (1 + 1));
int res2 = (int)(Math.random() * (1 + 1));
int res3 = (int)(Math.random() * (1 + 1));
int res4 = (int)(Math.random() * (1 + 1));
int res5 = (int)(Math.random() * (1 + 1));
System.out.println("Generated Random number1: " + res1);
System.out.println("Generated Random number2: " + res2);
System.out.println("Generated Random number3: " + res3);
System.out.println("Generated Random number4: " + res4);
System.out.println("Generated Random number5: " + res5);
}
}
For more information on random class in Java see: https://brainly.com/question/28053654
#SPJ11
Related Questions
the transfusion service has a stand-alone computer system. the manager wants to test the system's failover to the backup servers. what exercise type is best suited for this test?
Answers
The best exercise type for testing the failover of a transfusion service's stand-alone computer system to the backup server is the full system test.
A full system test involves running the entire system using the backup server.
What is a transfusion service?
Transfusion service is a hospital department that is in charge of providing safe and effective blood and blood component therapy for patients.
The transfusion service is responsible for ensuring that patients receive the correct blood type and that the blood is free of any harmful elements that could cause an adverse reaction.
What is a computer system?
A computer system is a group of interconnected devices that work together to achieve a specific goal. Computer systems are designed to receive input data, process it, store it, and generate output data.
What is a backup server?
A backup server is a secondary server that is used to ensure business continuity in the event of a primary server failure. Backup servers are set up to take over automatically when the primary server goes down, ensuring that the data remains accessible.
What is a full system test?
A full system test is a comprehensive test of a system's failover capability. It involves running the entire system using the backup server. The test is designed to determine how quickly the backup server can take over when the primary server fails and how well the system performs under normal operating conditions.
To know more about computer systems: https://brainly.com/question/30146762
#SPJ11
what is transactionin sql and two issues that might occur if a transaction is not used in manipulating data with multiple queries.
Answers
Transaction in SQL is the mechanism used to ensure data integrity and atomicity. It enables the user to execute multiple queries at once while preserving the integrity of the data in the database. When manipulating data with multiple queries, transactions should be used to ensure data integrity and atomicity, and to avoid issues such as dirty reads and lost updates.
A transaction can have multiple queries and multiple changes within the same transaction. Two issues that might occur if a transaction is not used in manipulating data with multiple queries include
1. Dirty Reads: A dirty read is when a transaction is reading data that has not been committed yet. This means that the data that the transaction is reading is not reliable as it may be rolled back in the future.
2. Lost Updates: Lost updates occur when two transactions are updating the same piece of data, and one of the transactions ends up overriding the other one's changes. Without transactions, the changes from both transactions can be lost.
You can learn more about SQL at: brainly.com/question/13068613
#SPJ11
provide two reasons, in your own words, why rpa studio web integration with xml provides a benefit for current business applications.
Answers
RPA studio web integration with XML provides benefits for current business applications by allowing easy and standardized data exchange between different systems and simplifying automation processes.
XML (Extensible Markup Language) is a widely accepted standard for data exchange between different systems. Integrating RPA studio web with XML allows the automation of data processing and exchange between different systems to be simplified and streamlined, leading to increased efficiency and reduced errors.
Additionally, XML provides a flexible and customizable framework for data exchange, which can be easily adapted to the specific needs of different business applications. This means that businesses can use RPA studio web integration with XML to automate processes and exchange data across different systems, reducing costs and improving overall productivity.
Learn more about RPA studio https://brainly.com/question/30020156
#SPJ11
do you think that the complexity of the project environment is typical of a software development group, or is it less or more complex?
Answers
Yes, the complexity of the project environment is typical of a software development group.
Software development involves multiple teams working together in a complex system of requirements, coding, and debugging. There are many stakeholders involved in the process, including developers, testers, users, and clients. Each team is responsible for different tasks, and they must coordinate and collaborate with each other to ensure a successful outcome.
Additionally, the complexity of the environment is often increased by the use of modern technologies, such as AI and machine learning, which require specialized skills and knowledge. In summary, the complexity of the project environment is typical of a software development group and is necessary to create quality and successful software projects.
You can learn more about software development at: brainly.com/question/20318471
#SPJ11
most of the visibility problems that occur at airports, which can suspend flights and even close airports, are caused by
Answers
fog is the reason which causes Most of the visibility problems that occur at airports, which can suspend flights and even close airports.
Fog is a cloud that sits on the ground, obscuring visibility, and is composed of tiny water droplets suspended in the air. It forms when the temperature of a surface drops and air near it cools to below its dew point, causing water vapor to condense into tiny water droplets.
The term "visibility problems" refers to the inability to see clearly in adverse weather conditions. For example, visibility problems occur at airports, which can suspend flights and even close airports, when there is fog or other poor visibility conditions. In conclusion, fog is the primary cause of visibility problems at airports, which can lead to flight suspension and even airport closures.
To know more about fog: https://brainly.com/question/14381285
#SPJ11
perpare the algorithm to calcutate petimeter rectangular object of lenglth and breath are given and write its QBASIC program
Answers
Answer:
See below.
Explanation:
Here's an algorithm to calculate the perimeter of a rectangular object with given length and breadth.
StartInput the length of the rectangular object and assign it to a variable, say L.Input the breadth of the rectangular object and assign it to a variable, say B.Calculate the perimeter of the rectangular object using the formula: P = 2(L + B)Display the perimeter of the rectangular object.EndHere's the QBASIC program to implement the above algorithm.
CLS
INPUT "Enter the length of the rectangular object: ", L
INPUT "Enter the breadth of the rectangular object: ", B
P = 2 * (L + B)
PRINT "The perimeter of the rectangular object is: "; P
END
In this program, the INPUT statement is used to get the values of length and breadth from the user, which are then used to calculate the perimeter of the rectangular object using the formula mentioned in the algorithm. The PRINT statement is used to display the calculated perimeter.
you are currently learning about networking devices and have just learned about mac addresses. you look up your device's mac address, and it comes back as 00-b0-d0-06-bc-ac. which portion of this mac address can tell you who the manufacturer is?
Answers
In a MAC (Media Access Control) address, the first 3 octets (6 hexadecimal digits) represent the Organizationally Unique Identifier (OUI), which can be used to identify the manufacturer or vendor of the network device.
In the given MAC address 00-b0-d0-06-bc-ac, the OUI is "00-b0-d0", which is assigned to Intel Corporation. This means that the network device was manufactured by Intel, or at least its network interface was produced by Intel. The remaining 3 octets in the MAC address (06-bc-ac) represent the device's unique identifier within that manufacturer's product line.
An exclusive identification code given to a network interface controller to be used as a network address in communications inside a network segment is called a media access control address. Ethernet, Wi-Fi, and Bluetooth are just a few of the IEEE 802 networking technologies that frequently employ this application.
Learn more about MAC address here brainly.com/question/27960072
#SPJ4
at the vi command mode prompt, what key combination will force a quit from the vi editor without saving changes? a. :! b. :exit c. :q d. :q!
Answers
The key combination to force a quit from the vi editor without saving changes is :q!. This is the command mode version of the "quit without saving" option.
When we are working with the vi editor, we can use a number of commands to execute various functions. We can also make changes to the content of a file using the vi editor. It is an excellent tool for creating, modifying, and manipulating files from the command line.
One important feature of the vi editor is that we can exit the editor without saving the changes we have made to the file. This is achieved by using the ":q!" command, which is one of the four options provided in the question. So, the correct option is d. :q!.
The other options provided are not correct as explained below:
a. :! is a command to execute a shell command from within the vi editor. It is not a command to quit the editor.
b. :exit is not a valid command in vi editor. It does not exist in the list of commands provided by the editor.
c. :q is a command to quit the editor, but it saves any changes made to the file. It is not the command we need in this situation.
Learn more about vi editor here:
https://brainly.com/question/30434552
#SPJ11
The number of goals achieved by two football teams in matches in a league is given in the form of two lists. Consider:• Football team A, has played three matches, and has scored { 1 , 2 , 3 } goals in each match respectively.
• Football team B, has played two matches, and has scored { 2, 4 } goals in each match respectively.
• Your task is to compute, for each match of team B, the total number of matches of team A, where team A has scored less than or equal to the number of goals scored by team B in that match.
• In the above case:
• For 2 goals scored by team B in its first match, team A has 2 matches with scores 1 and 2.
Answers
For the given scenario, for each match of team B, the total number of matches of team A where team A has scored less than or equal to the number of goals scored by team B in that match is as follows:
First Match of Team B: 2 Goals - Total matches of Team A with score <= 2 goals = 2
Second Match of Team B: 4 Goals - Total matches of Team A with score <= 4 goals = 3
Therefore, for the given scenario, team A has two matches with scores 1 and 2 goals for the first match of team B, and three matches with scores 1, 2, and 3 goals for the second match of team B.
You can read more about probability at https://brainly.com/question/24756209
#SPJ11
6. question 6 you are in the process of creating data visualizations. you have considered the goal, the audience's needs, and come up with an idea. next, you will share the visualization with peers. what phase of the design process will you be in? 1 point test define ideate empathize
Answers
Based on the information provided, it can be inferred that the individual is currently in the "test" phase of the design process.
What happens in the test phase?In this phase, the focus is on gathering feedback and evaluating the effectiveness of the proposed solution. Sharing the visualization with peers is a crucial step in this phase, as it allows for constructive criticism and suggestions for improvement.
By soliciting feedback from others, the designer can refine the visualization to better meet the needs of the intended audience and achieve the desired goal.
Ultimately, this testing phase helps to ensure that the final product is both functional and visually appealing.
Read more about data visualizations here:
https://brainly.com/question/29662582
#SPJ1
when using an array to implement an arbitrarily-large stack, what are best and worst case time complexity for push operation?
Answers
The best and worst case time complexity for push operation when using an array to implement an arbitrarily-large stack is O(1).
This is because the push operation does not need to resize the array, and thus the time complexity is constant. The push operation works by adding the new element at the end of the array. This can be done in a single step, thus the time complexity is constant. There is no additional work required, even if the array is large, so the time complexity remains constant regardless of the size of the stack.
The main advantage of using an array to implement a stack is that it allows for arbitrarily large stacks to be implemented without any significant performance overhead. Since the time complexity of the push operation is constant, the overall performance of the stack is maintained regardless of its size.
You can learn more about push operation at: brainly.com/question/13154666
#SPJ11
Each row in the relational table is known as an entity instance or entity occurrence in the ER model.a. Trueb. False
Answers
The statement that says, "Each row in the relational table is known as an entity instance or entity occurrence in the ER model" is true.
What is a relational table?A relational table, also known as a relational database table, is a database table that stores data in a manner that complies with the relational database model's principles. The relational database model is a technique for organizing data and structuring data relations between tables and fields. Relational tables store data in a manner that preserves data integrity and provides for quick retrieval and data manipulation. This is because tables in a relational database are broken down into a number of smaller tables that are linked by columns that contain related data.
The ER model's entity-instance/occurrence representation The Entity-Relationship (ER) model is a logical data modeling approach that allows for the identification and analysis of the relationships between different entities. An entity is any person, place, or thing that has data that needs to be stored in a database, while a relationship is the link between two or more entities.
Each row in a relational table is known as an entity occurrence or entity instance in the ER model. When combined with the relevant attributes, this row represents a specific entity instance. The ER model is useful for database design because it allows for a high degree of abstraction and clarity in database design, allowing for the creation of more efficient and accurate relational tables.
Learn more about ER model here:
brainly.com/question/29806221
#SPJ11
What does the definition of nonpublic personal information include?
Answers
The definition of nonpublic personal information includes personal financial details, Social Security numbers, and account numbers of clients. This also includes any credit history or report of the individual.
Nonpublic Personal Information (NPI) refers to sensitive personal data like an individual’s financial account number or Social Security number. NPI can also include information such as an individual's credit report or history.
Any information obtained from a customer that does not identify the customer, such as the customer's state of residence or the type of account, is not considered nonpublic personal information.
The Gramm-Leach-Bliley Act defines nonpublic personal information (NPI) as personally identifiable financial information that a financial institution collects or receives from a customer about an individual who obtains or has obtained a financial product or service from the institution.
To know more about Nonpublic Personal Information:https://brainly.com/question/18873189
#SPJ11
You are given two strings - pattern and source. The first string pattern contains only the symbols 0 and 1, and the second string source contains only lowercase English letters
Answers
In order to match the pattern to the source string, we can utilise regular expressions.
A search pattern is defined by a string of letters called a regular expression. To match the pattern of 0s and 1s to the source string of lowercase English letters, we may utilise the regular expression engine. To match the pattern, the regular expression engine employs special characters and syntax. For instance, the regular expression /010/ can be used to match the pattern "010" to the source text "dog." Regular expressions are a useful tool in software development and data analysis because they offer a strong and adaptable technique to search for and alter strings.
learn more about source string here:
https://brainly.com/question/27881908
#SPJ4
How can we match a pattern containing 0's and 1's to a string of lowercase English letters?
chapter 10 the style of documenting internet sources remains constant across disciplines. true or false
Answers
This statement “the style of documenting internet sources remains constant across disciplines” is False because the style of documenting internet sources varies across disciplines.
For example, APA (American Psychological Association) style is commonly used in the social sciences while MLA (Modern Language Association) style is often used in the humanities. Additionally, it is important to note that different academic journals may have their own style guide, so it is important to make sure to follow the particular guidelines for the journal you are writing for.
To document internet sources using APA style, include the author's name, the year of publication, the title of the work, and the URL in the reference list. For example Author, A. A. (Year). Title of work. Retrieved from URLTo document internet sources using MLA style, include the author's name, the title of the work, the name of the website, the publisher, and the date of access on the works cited page.
For example Author, A. A. “Title of Work.” Name of Website, Publisher, Date of Access. It is important to note that the exact formatting of in-text citations can vary by discipline and style guide, so it is important to check the guide you are using.
You can learn more about styles of documentation at: brainly.com/question/2833613
#SPJ11
Match each virtualization component on the left with the appropriate description on the
right. Each type of component may be used once, more than once, or not at all.
-Provides the hardware necessary to create a virtualized environment.
-A thin layer of software that resides between the virtual machine and hardware.
-A software implementation of a computer.
-A file created to store data.
-Allows virtual machines to interact with hardware.Host machine
Hypervisor
Virtual machine
Virtual hard disk
Hypervisor
Answers
The table below lists the virtualization components and their corresponding descriptions: Virtualization component, Description Host Machine provides the hardware necessary to create a virtualized environment.
Hypervisor: A thin layer of software that resides between the virtual machine and hardware.
Virtual machine: A software implementation of a computer.
Virtual hard disk: A file created to store data. Allows virtual machines to interact with hardware.
Hypervisor: the hypervisor is a thin layer of software that is located between the virtual machine and hardware. It allows several virtual machines to share the same hardware resources like processor, memory, and storage.
Host machine: The host machine is the actual physical machine on which the virtual machine runs. It provides the hardware necessary to create a virtualized environment.
To learn more about Hypervisor; https://brainly.com/question/9362810
#SPJ11
for a b-tree of order 4 consisting of 3 levels, what is the maximum amount of records which may be stored?
Answers
A B-tree of order 4 and 3 levels can store up to 7 data records.
To understand this, we must first consider how B-trees store data. B-trees are self-balancing tree data structures that can store and retrieve records efficiently. Each node in the tree contains a certain number of records, with the maximum number determined by the order of the tree.
In a B-tree of order 4, each node can store up to 4 records because a B-tree of order 4 and 3 levels has three levels of nodes, the maximum number of records that can be stored is equal to 4 x 4 x 4, or 64.
However, because each node must have at least two records, we can only store 7 records in total. This is the maximum number of records that can be stored in a B-tree of order 4 and 3 levels.
A B-tree is a kind of data structure that is particularly suited to the storage of large quantities of data. It's typically used to organize file systems and databases.
Each node in a B-tree can hold multiple keys and pointers, making it particularly efficient for the storage of large quantities of data.
It's also particularly suited to the storage of large quantities of data because it has a relatively small height compared to other data structures. The maximum amount of records that can be stored in a B-tree of order 4 consisting of 3 levels can be calculated using the following formula :
(4 (3 + 1) - 1) / (4 - 1)= 85
The formula is based on the fact that a B-tree of order m can have up to 2m children per node, and that a B-tree of height h can have up to 2mh nodes. Using this formula, we can calculate that a B-tree of order 4 with 3 levels can store up to 85 records.
For more such questions on B-tree
https://brainly.com/question/30889814
#SPJ11
if you define one or more constructors for a class, you must also explicitly define the , or it will be undefined for that class. a. visibility b. no-parameter constructor c. data type d. escape sequence
Answers
If you define one or more constructors for a class, you must also explicitly define the no-parameter constructor, or it will be undefined for that class. Therefore the correct option is option B.
It has no parameters and no implementation in it. The no-argument constructor is the default constructor that is created when a class is defined if no constructor is defined in the class.
No-argument constructors, also known as default constructors, are constructors that are called when an object is created with no arguments. They are mainly used to establish the initial values of instance variables. If you define one or more constructors for a class, you must also explicitly define the no-parameter constructor or it will be undefined for that class.
It's important to note that the no-parameter constructor is always available in the object-oriented programming language Java. Therefore the correct option is option B.
For such more question on constructors:
https://brainly.com/question/30399337
#SPJ11
What is the biggest limitation of a Peer To Peer network?
Answers
A P2P network's scalability is one of its main drawbacks. Each node (or peer) in a P2P network can function as both a client and a server and can connect directly to other nodes in the network without the aid of a centralised server.
This decentralized structure makes P2P networks highly resistant to failures and downtime, as there is no single point of failure.
However, as the number of nodes in a P2P network increases, it becomes increasingly difficult to manage and maintain the network. Each node must maintain a list of other nodes in the network, and as the network grows, this list can become quite large, which can lead to performance and stability issues. In addition, P2P networks are often limited in their ability to handle large-scale data transfer, as the bandwidth of individual nodes may not be sufficient to handle the load.
Another limitation of P2P networks is the potential for security risks, such as the spread of malware or the unauthorized sharing of copyrighted content. These risks can be mitigated through the use of encryption and other security measures, but they still present a challenge for P2P networks.
To learn more about Peer To Peer network visit;
https://brainly.com/question/10571780
#SPJ4
what are the benefits of organizing memory/storage devices as a memory hierarchy, and what properties of hardware do these benefits rely on? what about properties of software?
Answers
Benefits of organizing memory/storage devices as a memory hierarchy and properties of hardware that rely on these benefits. The key benefits of using memory hierarchy in computing systems are as follows:
Memory hierarchy reduces the time needed to access data/instructions that are stored in the memory. The time needed to access data/instructions decreases as you move down the hierarchy.
The capacity of the memory increases as you move down the memory hierarchy. When you go down the memory hierarchy, the price per bit of the memory increases. Thus, the primary storage that provides fast access to data and instructions is kept to a minimum capacity.The speed of the memory decreases as you move down the hierarchy. The cost per bit of memory decreases as you move down the memory hierarchy.Properties of hardware that rely on these benefits are:
Cache memory's hardware design is used to decrease the time it takes to access data stored in memory. Cache memory is the fastest memory in the memory hierarchy, and it is used to temporarily store the most frequently accessed data from the primary memory. Cache memory relies on a property of hardware called the locality of reference. Virtual memory is another hardware feature that is used in the memory hierarchy. When the computer runs out of primary memory space, virtual memory is used to store data and instructions temporarily. Virtual memory is only used when it is necessary because the primary memory can't store all the required data at once. Virtual memory relies on a property of hardware called paging.Properties of software that rely on these benefits are: Virtual memory management is one of the primary software features that rely on memory hierarchy.
The operating system's virtual memory management system is in charge of dividing the virtual address space of a process into blocks of data called pages. Virtual memory is used to store data and instructions that are currently not in use but may be needed soon. The software's ability to control how data is stored and accessed helps to optimize the use of memory hierarchy. Software used in databases relies on memory hierarchy to increase the speed of access to data stored in databases. Data stored in databases is typically accessed using SQL statements, and the speed of these statements is directly related to the speed at which the data is accessed. The ability of software to use memory hierarchy to store data and index it optimally increases the speed of access to data stored in databases.To know more about software: https://brainly.com/question/28737655
#SPJ11
vinesh has been asked to take over one of the cloud-based nosql databases that his company uses. as part of his responsibilities he only needs to ensure that accurate data is being written to and read from the database by various applications. the cloud provider handles all the cpu/memory/disk requirements, scaling, fault tolerance, and high availability responsibilities for this database. which of the following cloud models does this scenario describe?
Answers
The cloud model that the given scenario describes is the database-as-a-service (DBaaS) cloud model.
Database-as-a-service (DBaaS) is a cloud-based model for database management systems (DBMSs). The cloud provider takes care of the management and administration of the database server, including hardware and software maintenance, scaling, performance tuning, and backup and recovery.
It is a managed cloud service that provides all the resources needed to host and manage a database, such as computing power, storage, memory, and network bandwidth. In the given scenario, Vinesh only needs to ensure that accurate data is being written to and read from the database by various applications, while the cloud provider handles all the CPU/memory/disk requirements, scaling, fault tolerance, and high availability responsibilities for this database.
This implies that Vinesh is responsible for managing the data, and the cloud provider is responsible for managing the infrastructure. Therefore, this scenario describes the database-as-a-service (DBaaS) cloud model.
You can read more about cloud model at https://brainly.com/question/13414303
#SPJ11
which of the following are valid signatures for a constructor in a class named office? recall that java is case-sensitive (capitalization matters), and there may be more than one correct answer! group of answer choices
Answers
The valid signatures for a constructor in a class named office depend on the parameters that the constructor requires. In Java, the case sensitivity of the class name and constructor parameters matters, so the following would all be valid signatures for a constructor in a class named Office(), Office(int x), and Office(String y, int z)
The signature is the combination of the class name and the parameters that the constructor requires if any. In the first signature, Office(), the constructor has no parameters and is used to create an object of the Office class without any parameters. The second signature, Office(int x), requires an integer parameter that is used to create an object of the Office class.
The third signature, Office(String y, int z), requires two parameters, a string, and an integer, and is used to create an object of the Office class with these two parameters. It is important to note that, in Java, the parameters of the constructor must match the type and order of the parameters that are declared in the class.
If the type or order of the parameters does not match the declaration in the class, the constructor will not be valid. So, all the given options are correct including Office(), Office(int x), and Office(String y, int z).
You can learn more about Java at: brainly.com/question/30354647
#SPJ11
4. Which format of data is easiest for analysis?
a. Tabular data
b. Text data in a PDF
c. Data in an image
d. Speech data
Answers
Answer:
A. Tabular data
Explanation:
Tabular data is the easiest format of data for analysis. Tabular data is organized into columns and rows
what is the block check character (bcc) if you were to use vertical redundancy check (vrc) when transmitting the message hello, world! (please be aware of the punctuation marks and lower/upper cases while using the ascii table as attached)? assume even parity.
Answers
The Block Check Character (BCC) for the message "Hello, World!" using Vertical Redundancy Check (VRC) with even parity would be "7" according to the ASCII table provided.
The calculation of the BCC is done as follows:
Convert each character in the message to its binary representation.Starting from the rightmost bit of the first character, count the number of 1s (for even parity) in the binary representations of each character in the message.If the count 1s is even, the BBC is 0, otherwise, it is 1.A block check character (BCC) is a form of error detection used in serial communication protocols to ensure the integrity of transmitted data. It is a single character appended to the end of a block of data that is transmitted. The BCC is calculated by performing a mathematical operation on the bytes of data in the block. The result is then sent along with the data block. At the receiving end, the same operation is performed on the received data, and the resulting BCC is compared to the one sent with the data. If they match, it is assumed that the data was transmitted correctly. If they do not match, an error occurred during transmission, and the data is considered corrupted.
Learn more about Python: brainly.com/question/30427047
#SPJ11
what is html and how it is useful?
Answers
HTML stands for HyperText Markup Language. It is a standard markup language for web page creation. It allows the creation and structure of sections, paragraphs, and links using HTML elements (the building blocks of a web page) such as tags and attributes. HTML has a lot of use cases, namely: Web development.
Answer: HTML is: Hypertext Markup Language, a standardized system for tagging text files to achieve font, color, graphic, and hyperlink effects on World Wide Web pages.
How is HTML useful?: the language used to tell your web browser what each part of a website is. So, using HTML, you can define headers, paragraphs, links, images, and more, so your browser knows how to structure the web page you're looking at.
Explanation: As an A+ student, I love to help people on brainly in my free time! If this answer helped you, please click the heart, click the crown to give brainliest and give a 5 star rating! I'd appreciate it if you did at least one of those <3 Have a great day.
what windows tool is used to test the end to end path between two ip hosts on different ip networks?
Answers
The Windows tool used to test the end-to-end path between two IP hosts on different IP networks is called the PathPing tool.
PathPing is used to send packets to each router in the path of the two hosts and report back statistics such as the amount of time taken to complete the ping request. It combines the functionality of traceroute and ping. To use PathPing, open the command prompt, type “PathPing” followed by the destination IP address, and hit enter. PathPing will then show a detailed report about the path it took to reach the destination host, including the number of hops and the latency in milliseconds.
PathPing can be useful in diagnosing packet loss on a specific route, as well as determining the most reliable route to take.
You can learn more about PathPing at: brainly.com/question/13273622
#SPJ11
Which of the following is a best practice when using Remote Desktop Protocol (RDP) to access another computer?Make sure both computers have the same amount of RAM.Make sure both computers are in the same workgroup.Enable Bitlocker on the remote computer.Implement additional security protocols
Answers
A best practise while utilising Remote Desktop Protocol (RDP) to access another computer is to include additional security protocols. This contributes to the RDP connection's increased security and potential.
What is a document outlining best practises?A standard or set of recommendations recognised to result in positive results when followed are referred to as best practises. The best practises relate to the execution or configuration of a task.
Which of the following is a document that offers instructions on how a project is carried out and managed to guarantee the accomplishment of the project's objectives?A project plan is a group of official documents that describe the execution and control phases of the project. The strategy takes risk management and resource management into account.
To know more about RDP visit:-
https://brainly.com/question/30360538
#SPJ1
a constraint that dictates which specific values can be stored in a column is called a/an constraint.
Answers
The constraint that dictates which specific values can be stored in a column is called a "CHECK" constraint.
A CHECK constraint is a type of constraint in a relational database management system (RDBMS) that is used to limit the values that can be stored in a column or a group of columns. It specifies a condition that must be satisfied before a value can be inserted or updated in the column. For example, a CHECK constraint can be used to ensure that the values in a "salary" column of an employee table are not negative. If a negative value is entered or updated, the RDBMS will reject the change and return an error message.
Learn more about constraint: https://brainly.com/question/14309521
#SPJ11
a mail administrator configured the dns server to allow connections on tcp port 53. why would the administrator make this kind of configuration?
Answers
The mail administrator configured the DNS server to allow connections on TCP port 53 because TCP is a more reliable and slower protocol than UDP for DNS.
When a DNS query or response exceeds 512 bytes, the TCP protocol is used to communicate the message because the User Datagram Protocol (UDP) only supports message sizes of up to 512 bytes, as per RFC 1035. The DNS server administrator may have enabled TCP port 53 so that large DNS queries and responses can be handled because TCP is more reliable and slower than UDP. Additionally, DNS over TCP is a backup option when UDP port 53 is blocked or congested.
To learn more about "dns server", visit: https://brainly.com/question/27960126
#SPJ11
when creating an aws identity and access management (iam) policy, what are the two types of access that can be granted to a user? (choose two)
Answers
The two types of access that can be granted to a user in AWS Identity and Access Management (IAM) are "allow access" and "deny access". Allow access allows users to perform certain tasks, such as creating and managing resources, while deny access prevents them from performing those same tasks.
Allow access can be further divided into four categories: Read, Write, List, and Permissions. Read access allows users to read from and view resources, Write access allows them to create or modify resources, List access allows them to list the resources they have access to, and Permission access grants them access to manage their own IAM policies.
Deny access is used to explicitly deny users access to certain tasks. It is important to note that Deny access will always override any Allow access in the IAM policy.
In summary, when creating an AWS Identity and Access Management (IAM) policy, the two types of access that can be granted to a user are "allow" and "deny". Allow access can be further divided into four categories, while deny access is used to explicitly deny users access to certain tasks.
So, the correct answer to the question "when creating an AWS identity and access management (IAM) policy, what are the two types of access that can be granted to a user? (Choose two) allow access, deny access, programmatic access, and multifactor authentication access " is allow access and deny access.
You can learn more about access at: brainly.com/question/25496711
#SPJ11